runesleo
用户暂无简介
runesleo
今天把 PM 策略仓库搞挂了。
我习惯多终端开窗口干活:一个跑 Codex 研究策略/数据,一个跑 Claude 推进其他工作,再开一个处理杂项,慢慢就会开好几个终端窗口。我以为它们各干各的。结果俩都在改同一个 .ts,git 状态炸成一团,修了俩小时。
都在聊 multi-agent 怎么协同。很少人聊它在 git 层面是什么样。
两个 agent 在 git 眼里 = 两个我。同一个文件互相踩,分支状态打架。修法不在 prompt,在仓库结构。
立了条新铁律,4 点:
1. 高风险 repo 禁止主仓库直接编辑,主 repo 当干净底盘
2. 每个任务进独立 worktree,slug = 策略号 + 动作(h12-cancel-sync / pnl-script-v8)
3. active-tasks JSON 加 worktree_path 字段,开第二窗口前 grep 防重复
4. 完成回主 repo,删 worktree + 删分支
先找单一项目试点跑了一天,零冲突。再慢慢扩到其他项目。
multi-agent 最难的不是它们怎么对话,是它们别打架。
我习惯多终端开窗口干活:一个跑 Codex 研究策略/数据,一个跑 Claude 推进其他工作,再开一个处理杂项,慢慢就会开好几个终端窗口。我以为它们各干各的。结果俩都在改同一个 .ts,git 状态炸成一团,修了俩小时。
都在聊 multi-agent 怎么协同。很少人聊它在 git 层面是什么样。
两个 agent 在 git 眼里 = 两个我。同一个文件互相踩,分支状态打架。修法不在 prompt,在仓库结构。
立了条新铁律,4 点:
1. 高风险 repo 禁止主仓库直接编辑,主 repo 当干净底盘
2. 每个任务进独立 worktree,slug = 策略号 + 动作(h12-cancel-sync / pnl-script-v8)
3. active-tasks JSON 加 worktree_path 字段,开第二窗口前 grep 防重复
4. 完成回主 repo,删 worktree + 删分支
先找单一项目试点跑了一天,零冲突。再慢慢扩到其他项目。
multi-agent 最难的不是它们怎么对话,是它们别打架。
- 赞赏
- 点赞
- 评论
- 转发
- 分享
5 天监控自己的工具,306 次触发,100% 误报。原来我一直在吸它自己的尾气🤦
给 Claude Code 加了个 hook,ssh 跨机器或写关键文件前弹横幅提醒一下,怕自己手快违反 SSOT 铁律。
配套 stats 脚本统计触发次数,今天打开样本一看,全是误报。
bug 不在 hook,在 stats 脚本:它 grep 的是日志里 "⚠️ 跨机器" 这串字符。
但日志里至少有三种回声:hook 自己输出的横幅、工具结果把横幅复述了一遍、连任务描述里写 "hook 这周触发 N 次" 都被算进去。
我数的不是触发次数,是工具自己说话的回音。
修法:让工具自己写 audit log。
log_trigger() { echo "{ts,hook,pattern,target}" >> ~/.claude/logs/hook-trigger.jsonl }
工具触发自己记一行,下周用真数据复盘。
监控自己的工具,最容易骗你的就是它自己。
Claude Code 的 hook 也好,埋点 SDK、agent 监控也好,只要监控对象包括"自己",事后 grep 就是循环陷阱。
它的输出会塞回日志、复述、甚至混进任务描述里,分不清哪条是真触发哪条是它自己讲过的话。
想知道工具被用了多少次,得让它自己说,别让日志替它说。
给 Claude Code 加了个 hook,ssh 跨机器或写关键文件前弹横幅提醒一下,怕自己手快违反 SSOT 铁律。
配套 stats 脚本统计触发次数,今天打开样本一看,全是误报。
bug 不在 hook,在 stats 脚本:它 grep 的是日志里 "⚠️ 跨机器" 这串字符。
但日志里至少有三种回声:hook 自己输出的横幅、工具结果把横幅复述了一遍、连任务描述里写 "hook 这周触发 N 次" 都被算进去。
我数的不是触发次数,是工具自己说话的回音。
修法:让工具自己写 audit log。
log_trigger() { echo "{ts,hook,pattern,target}" >> ~/.claude/logs/hook-trigger.jsonl }
工具触发自己记一行,下周用真数据复盘。
监控自己的工具,最容易骗你的就是它自己。
Claude Code 的 hook 也好,埋点 SDK、agent 监控也好,只要监控对象包括"自己",事后 grep 就是循环陷阱。
它的输出会塞回日志、复述、甚至混进任务描述里,分不清哪条是真触发哪条是它自己讲过的话。
想知道工具被用了多少次,得让它自己说,别让日志替它说。
- 赞赏
- 点赞
- 评论
- 转发
- 分享
Leo Labs 大群 4/26 群友讨论精华(最近 380 条)
━━━━━━━━━━━━
1️⃣ 凯利公式被群里集体否定 — 一致换回固定仓位
群里 30+ 分钟讨论仓位管理:
• "凯利需要知道真实概率,散户根本算不出"
• "凯利是稳定盈利前提下的优化方法,本身不能决定盈亏,吹成系统必备属于乱扯"
• 多人收敛实操:固定仓位 + 赚了就提本金 + 不随便改参数
• 一句金句:"你是上帝那么可以用凯利公式"
💡 回撤了想改参数 ≠ 仓位问题,那是策略本身的问题。
━━━━━━━━━━━━
2️⃣ 0.99 极端价格策略 — 验证窗口的统计学陷阱
群友抛出"买 0.99 能活吗",引出最好的统计学讨论:
• 99% 反转概率 = 1/1000
• 98% 反转概率 = 5/1000
• 想买 0.99 必须真胜率 >99%,但散户短期内根本验证不出来
• 一个比喻最直观:"我有 2 个硬币,一个 99% 正面 vs 99.5% 正面,得抛几百次才能分辨是哪个"
💡 你的策略可能不是"不行",是你撑不到验证它行不行的那一刻。
━━━━━━━━━━━━
3️⃣ 模拟盘 vs 实盘 gap 的真实数字
• 模拟 ROI 2.5% → 实盘亏
• 模拟 ROI 5% → 实盘还是亏
• 模拟 80% 胜率 → 实盘成交率不到 40%,能拿到的都是烂单
• 实盘门槛:"下单 50%
━━━━━━━━━━━━
1️⃣ 凯利公式被群里集体否定 — 一致换回固定仓位
群里 30+ 分钟讨论仓位管理:
• "凯利需要知道真实概率,散户根本算不出"
• "凯利是稳定盈利前提下的优化方法,本身不能决定盈亏,吹成系统必备属于乱扯"
• 多人收敛实操:固定仓位 + 赚了就提本金 + 不随便改参数
• 一句金句:"你是上帝那么可以用凯利公式"
💡 回撤了想改参数 ≠ 仓位问题,那是策略本身的问题。
━━━━━━━━━━━━
2️⃣ 0.99 极端价格策略 — 验证窗口的统计学陷阱
群友抛出"买 0.99 能活吗",引出最好的统计学讨论:
• 99% 反转概率 = 1/1000
• 98% 反转概率 = 5/1000
• 想买 0.99 必须真胜率 >99%,但散户短期内根本验证不出来
• 一个比喻最直观:"我有 2 个硬币,一个 99% 正面 vs 99.5% 正面,得抛几百次才能分辨是哪个"
💡 你的策略可能不是"不行",是你撑不到验证它行不行的那一刻。
━━━━━━━━━━━━
3️⃣ 模拟盘 vs 实盘 gap 的真实数字
• 模拟 ROI 2.5% → 实盘亏
• 模拟 ROI 5% → 实盘还是亏
• 模拟 80% 胜率 → 实盘成交率不到 40%,能拿到的都是烂单
• 实盘门槛:"下单 50%

- 赞赏
- 点赞
- 评论
- 转发
- 分享
Cursor 好大方,一下送 10000美金的 token额度,5月底到期。
最早接触 vibe coding 的时候重度用过一段时间 Cursor 后来逐渐转移到了 cc 和 codex 为主;
想不到又有机会可以重新研究 Cursor 看能搞出什么好玩好用的产品和工具,这下有的玩了!
感谢 @cursor_ai @edwinarbus 🙏
最早接触 vibe coding 的时候重度用过一段时间 Cursor 后来逐渐转移到了 cc 和 codex 为主;
想不到又有机会可以重新研究 Cursor 看能搞出什么好玩好用的产品和工具,这下有的玩了!
感谢 @cursor_ai @edwinarbus 🙏
- 赞赏
- 点赞
- 评论
- 转发
- 分享
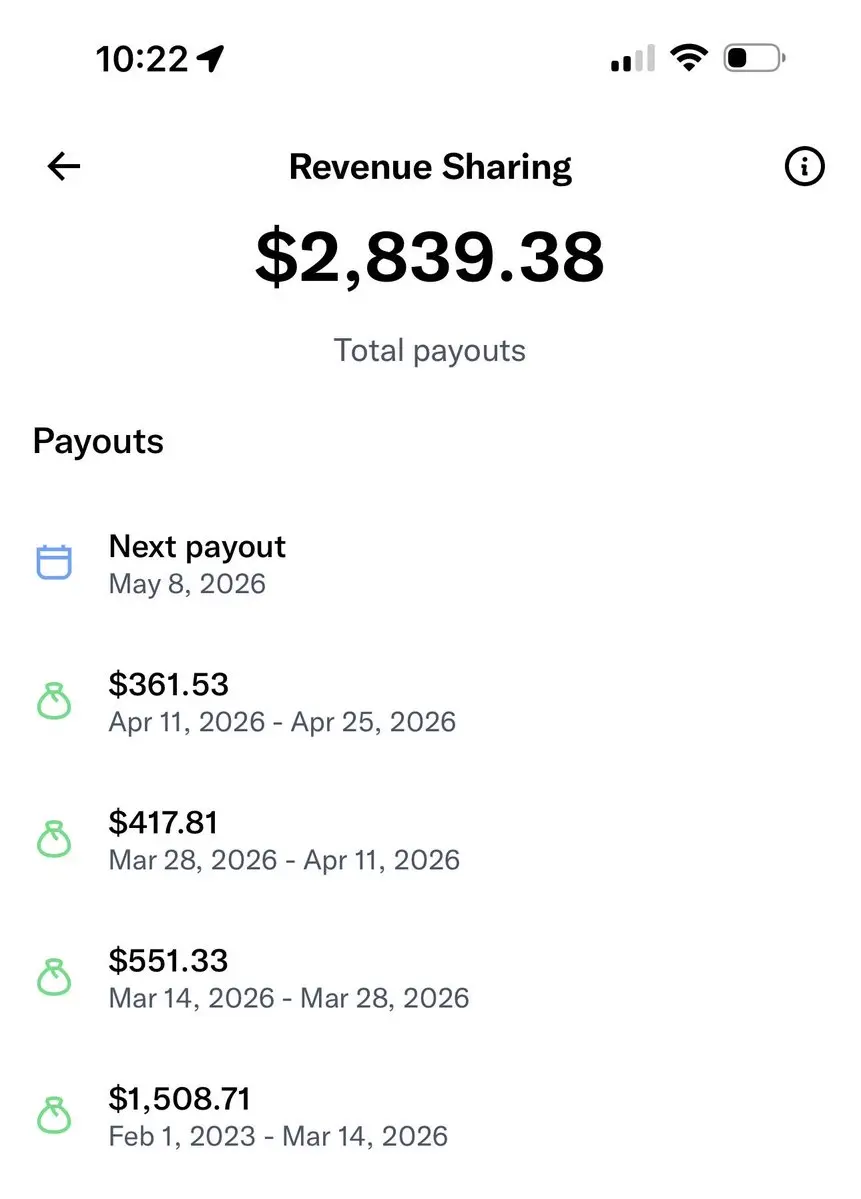
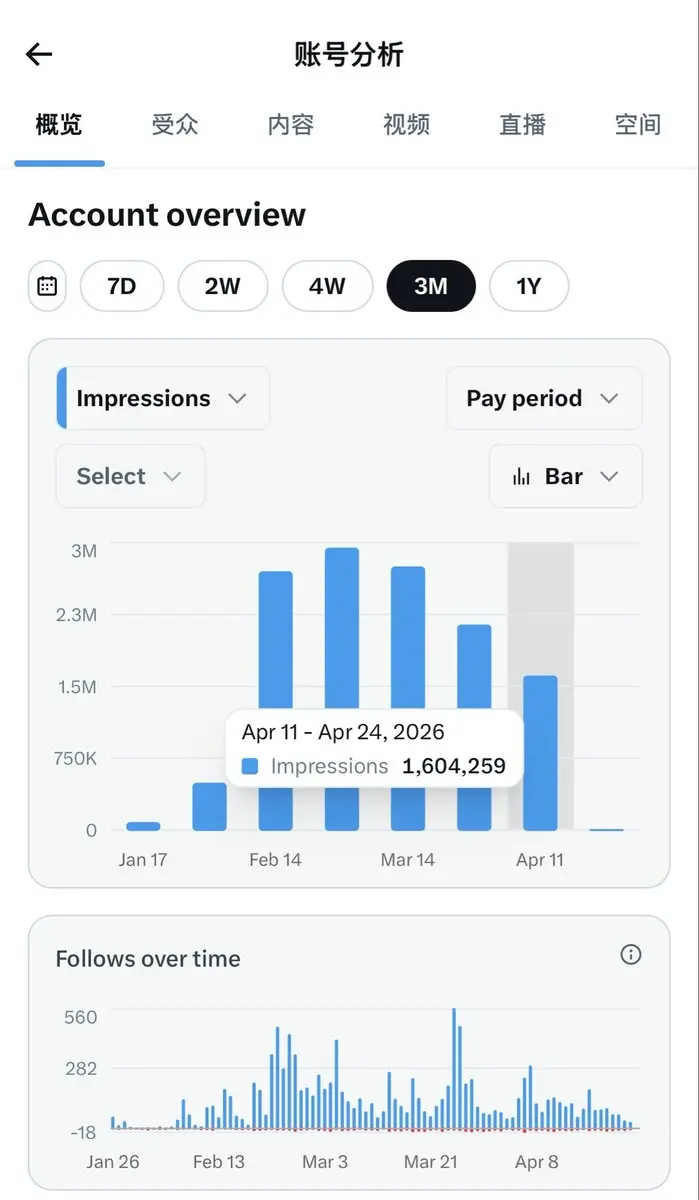
Thank you Elon
虽然变少了,但比预期的多
每一百万展示大概对应225美金
虽然变少了,但比预期的多
每一百万展示大概对应225美金
- 赞赏
- 点赞
- 评论
- 转发
- 分享
用 AI 用得脾气都变差了
它能干的事越多,我对结果的要求就跟着涨。觉得它应该越来越好,所以没做好的时候是真的会很生气。😠
它能干的事越多,我对结果的要求就跟着涨。觉得它应该越来越好,所以没做好的时候是真的会很生气。😠
- 赞赏
- 点赞
- 评论
- 转发
- 分享
做 Polymarket 的自动策略,部署一次大家都很小心,但停用的时候基本没人讲 —— 今天被这个盲点教训了 14 小时。
3 周前我停了一个在 Polymarket 上跑的策略机器人。pm2 stop,看到状态变成 stopped,就以为事情过去了。
今天顺手做了 10 分钟的服务器清理,重启了一下进程管理器。那个"死透"3周的策略,复活了,还静静跑了 14 小时真钱模式。
查了下根因 —— pm2 stop 只是把状态标记成"已停",没有真的删掉。只要一次批量启动,所有被"暂停"的进程都会被拉回来。这坑不是 pm2 独有的, systemd、docker、k8s 都是同一个问题:以为停了,其实没停。
做预测市场的自动策略,不管你用什么工具,停一个策略要做 5 件事:
1. 进程管理器层面彻底删除这个服务(不是暂停)
2. 从配置文件里移除这条定义(不然下次批量启动它会自己复活)
3. 在代码入口加一道关闭门(防止被误操作唤醒)
4. 更新你的文档或状态表(不然过两周你自己都忘了这个策略停了没)
5. 如果涉及交易账本,正式关闭这个策略的记账周期(epoch),防止新数据
混进旧策略的账
部署大家都很仔细,停用往往只做第 1 步就当完事。真正的坑都埋在第 2到第 5 步里。
14 小时样本小没亏钱,但这种侥幸不代表下次还能走运。
3 周前我停了一个在 Polymarket 上跑的策略机器人。pm2 stop,看到状态变成 stopped,就以为事情过去了。
今天顺手做了 10 分钟的服务器清理,重启了一下进程管理器。那个"死透"3周的策略,复活了,还静静跑了 14 小时真钱模式。
查了下根因 —— pm2 stop 只是把状态标记成"已停",没有真的删掉。只要一次批量启动,所有被"暂停"的进程都会被拉回来。这坑不是 pm2 独有的, systemd、docker、k8s 都是同一个问题:以为停了,其实没停。
做预测市场的自动策略,不管你用什么工具,停一个策略要做 5 件事:
1. 进程管理器层面彻底删除这个服务(不是暂停)
2. 从配置文件里移除这条定义(不然下次批量启动它会自己复活)
3. 在代码入口加一道关闭门(防止被误操作唤醒)
4. 更新你的文档或状态表(不然过两周你自己都忘了这个策略停了没)
5. 如果涉及交易账本,正式关闭这个策略的记账周期(epoch),防止新数据
混进旧策略的账
部署大家都很仔细,停用往往只做第 1 步就当完事。真正的坑都埋在第 2到第 5 步里。
14 小时样本小没亏钱,但这种侥幸不代表下次还能走运。
- 赞赏
- 1
- 评论
- 转发
- 分享
看 @predictionindex 这期最新预测市场数据周报告:Polymarket + Kalshi 合计约 75% 成交量,其余所有平台累计 <$30B。
报告里没讲的两个细节,对预测市场玩家其实更关键:
Kalshi 正在追上甚至反超 Polymarket
DeFiRate 最新一周:Kalshi $2.9B(60%),Polymarket $2.0B(40%)。两家在周度数据里互有拉锯——上周 Poly 刚反超过 Kalshi,这周又被追回去。
美国市场更极端。BofA 4/9-10 报告:Kalshi 89%,Polymarket 7%, 4%。合规 + KYC 是 Kalshi 的结构性优势,Polymarket 是链上协议,在美国散户覆盖上暂时吃亏,短期不会翻。
"双寡头"这个词容易让人以为 Poly 还是老大,美国市场实际已经基本是 Kalshi 一家。
"其他 25%" 里也许藏着更大的 alpha
Week 15 报告点到的小平台:Opinion / Limitless / Myriad / / Probable / / Chain)...
本质上是新预测市场上线到竞争充分之间的窗口期玩家。
一个典型数据:某链上钱包在 30 天做出 $99K PnL,每笔毛利率 ~21%。对比 Polymarket 成熟盘口的 0.5-2%,差了 10 倍以上。
报告里没讲的两个细节,对预测市场玩家其实更关键:
Kalshi 正在追上甚至反超 Polymarket
DeFiRate 最新一周:Kalshi $2.9B(60%),Polymarket $2.0B(40%)。两家在周度数据里互有拉锯——上周 Poly 刚反超过 Kalshi,这周又被追回去。
美国市场更极端。BofA 4/9-10 报告:Kalshi 89%,Polymarket 7%, 4%。合规 + KYC 是 Kalshi 的结构性优势,Polymarket 是链上协议,在美国散户覆盖上暂时吃亏,短期不会翻。
"双寡头"这个词容易让人以为 Poly 还是老大,美国市场实际已经基本是 Kalshi 一家。
"其他 25%" 里也许藏着更大的 alpha
Week 15 报告点到的小平台:Opinion / Limitless / Myriad / / Probable / / Chain)...
本质上是新预测市场上线到竞争充分之间的窗口期玩家。
一个典型数据:某链上钱包在 30 天做出 $99K PnL,每笔毛利率 ~21%。对比 Polymarket 成熟盘口的 0.5-2%,差了 10 倍以上。
- 赞赏
- 点赞
- 评论
- 转发
- 分享
又一件虽然没什么用但是很爽的事:今天用 Claude 把 3.7 万封 Gmail 收件箱清到 1.1 万。全程没自己看一封邮件,只点了两下:发 App Password、导入 filter。
走的是 Python + IMAP,分四步:
1. 导出所有发件人按频率分类
2. 555 个垃圾域名一键归档到 Archive-Junk
3. 主动停下来说「我误伤了 317 封银行 / 券商 / Coinbase / Claude 安全邮件,要召回吗」
4. 生成 Gmail Filter 让未来这些域名直接跳过 INBOX
第三步是我没料到的。本来准备自己抽查几封看分类对不对,AI 自己先把风险点列出来了。
走的是 Python + IMAP,分四步:
1. 导出所有发件人按频率分类
2. 555 个垃圾域名一键归档到 Archive-Junk
3. 主动停下来说「我误伤了 317 封银行 / 券商 / Coinbase / Claude 安全邮件,要召回吗」
4. 生成 Gmail Filter 让未来这些域名直接跳过 INBOX
第三步是我没料到的。本来准备自己抽查几封看分类对不对,AI 自己先把风险点列出来了。
- 赞赏
- 点赞
- 评论
- 转发
- 分享
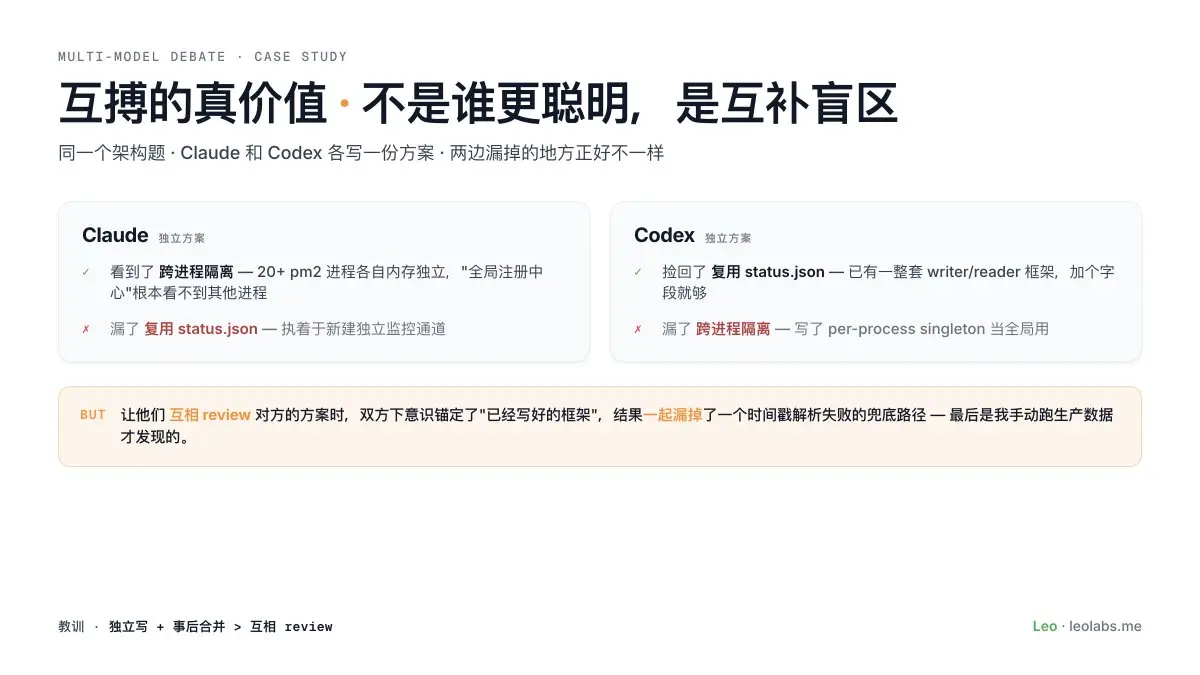
最近做了一次多模型互搏,有个挺有意思的发现。
同一个架构题,我分别让 Claude 和 Codex 独立写方案。
Codex 漏了一件事:我的策略分散在 20 多个独立的进程里,它写的方案默认"所有组件跑在同一个地方",直接无效。Claude 一眼看出这个问题。
反过来 Claude 漏了另一件事:它执着于新建独立的模块,其实我手里已经有一整套现成的框架可以搭车,加一个字段就够了。Codex 把这条捡了回来。
最有意思的是后面这步:我让两个模型互相 review 对方的最终方案,双方都下意识锚定了"对方已经写好的框架",结果一起漏掉了一个边界情况——最后是我手动跑生产数据才发现的。
所以现在的习惯是:每一轮互搏都给独立的成功标准,禁止让一个模型看另一个模型的底稿。拿到手的是两份盲区不重叠的独立底稿,合起来才接近完整。
同一个架构题,我分别让 Claude 和 Codex 独立写方案。
Codex 漏了一件事:我的策略分散在 20 多个独立的进程里,它写的方案默认"所有组件跑在同一个地方",直接无效。Claude 一眼看出这个问题。
反过来 Claude 漏了另一件事:它执着于新建独立的模块,其实我手里已经有一整套现成的框架可以搭车,加一个字段就够了。Codex 把这条捡了回来。
最有意思的是后面这步:我让两个模型互相 review 对方的最终方案,双方都下意识锚定了"对方已经写好的框架",结果一起漏掉了一个边界情况——最后是我手动跑生产数据才发现的。
所以现在的习惯是:每一轮互搏都给独立的成功标准,禁止让一个模型看另一个模型的底稿。拿到手的是两份盲区不重叠的独立底稿,合起来才接近完整。
- 赞赏
- 2
- 评论
- 转发
- 分享
做量化策略很容易犯的一个错:信任"看起来靠谱"的数据,不去跑上游。
我的天气策略之前覆盖 34 个城市,是过去几次扩张慢慢加出来的,很久没复查了。前两天例行 audit 随手拿 Polymarket 官方 API 拉了一遍全量市场,发现实际有 44 个——我自己漏了 10 个。
更有意思的是,顺手对比了行业里大家都在引用的那个天气工具站,它同样漏了其 中最大的一个:Panama City。这个城市在 Polymarket 上有 66 个事件选项,两份"看起来靠谱"的数据都没它。
教训:你自己一年前整理的列表会过期,别人整理的"行业清单"也会漏,只有原始 API 是对的。跑一遍成本没多少——这次我一次拉完就几分钟。
我的天气策略之前覆盖 34 个城市,是过去几次扩张慢慢加出来的,很久没复查了。前两天例行 audit 随手拿 Polymarket 官方 API 拉了一遍全量市场,发现实际有 44 个——我自己漏了 10 个。
更有意思的是,顺手对比了行业里大家都在引用的那个天气工具站,它同样漏了其 中最大的一个:Panama City。这个城市在 Polymarket 上有 66 个事件选项,两份"看起来靠谱"的数据都没它。
教训:你自己一年前整理的列表会过期,别人整理的"行业清单"也会漏,只有原始 API 是对的。跑一遍成本没多少——这次我一次拉完就几分钟。
- 赞赏
- 1
- 评论
- 转发
- 分享
一个做 YouTube Automation 的老哥,2018 年入行,累计赚了 200 万美元广告费。
他在最新视频里说:"Claude is 100% the best script writing and research AI tool. There's nothing better."(Claude 是最好的脚本写作和研究 AI 工具,没有之一。)
他不写代码,不在 AI 圈,纯粹是拿 Claude 写视频脚本写了几百条之后得出的结论。
说实话,AI 圈内互相吹"Claude 好用"我已经免疫了。但一个靠内容吃饭的人,用自己的钱订阅,拿真金白银验证过的评价——这种背书的分量不一样。
他在最新视频里说:"Claude is 100% the best script writing and research AI tool. There's nothing better."(Claude 是最好的脚本写作和研究 AI 工具,没有之一。)
他不写代码,不在 AI 圈,纯粹是拿 Claude 写视频脚本写了几百条之后得出的结论。
说实话,AI 圈内互相吹"Claude 好用"我已经免疫了。但一个靠内容吃饭的人,用自己的钱订阅,拿真金白银验证过的评价——这种背书的分量不一样。
- 赞赏
- 点赞
- 评论
- 转发
- 分享
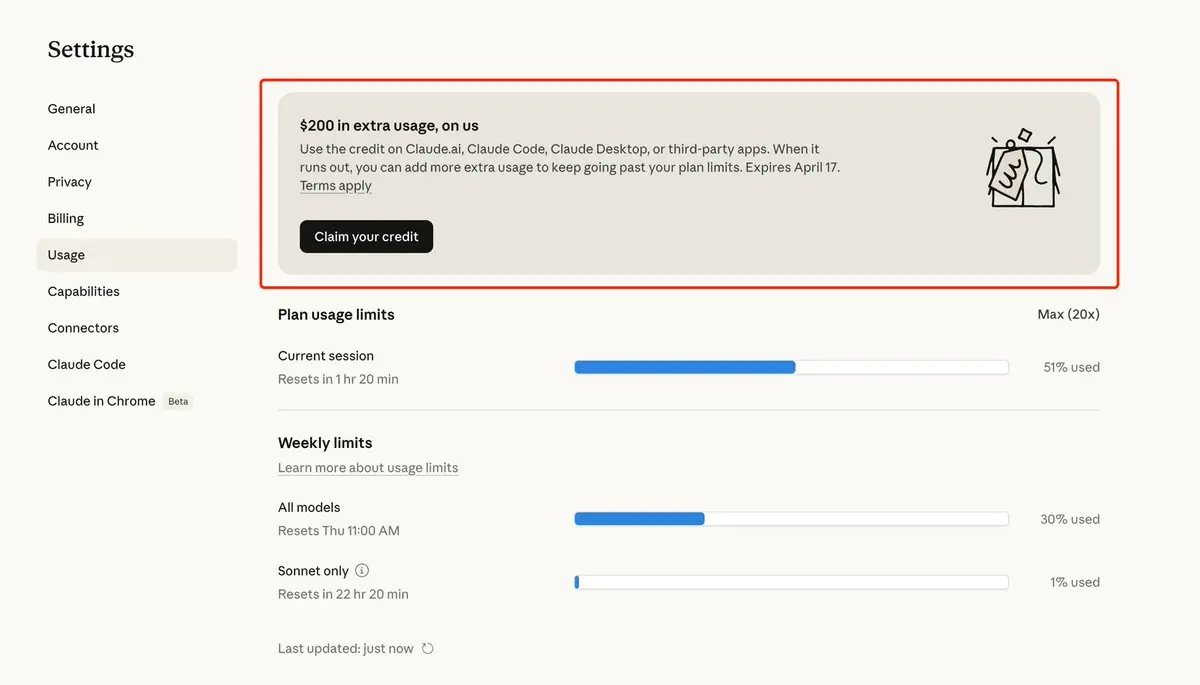
Claude 悄悄送了 $200 额度,藏在后台 Settings → Usage 里。
可以用在 Code、Claude Desktop、第三方 App,4 月 17 号过期。
注意:直接点 Claim 可能报错,先往下滑把 Extra usage 开关打开,再回去领就行了(app store订阅、没绑卡也成功哦)。
又可以开心的烧token了 !
可以用在 Code、Claude Desktop、第三方 App,4 月 17 号过期。
注意:直接点 Claim 可能报错,先往下滑把 Extra usage 开关打开,再回去领就行了(app store订阅、没绑卡也成功哦)。
又可以开心的烧token了 !
- 赞赏
- 2
- 评论
- 转发
- 分享
天气做市策略跑了一段时间,最近发现回撤不对劲。 一查,问题出在概率模型的两个假设上。
第一个:校准用的是网格再分析数据,但 Polymarket 结算用的是机场实测。两套数据源之间有系统性偏差 ,校准出来的 σ 从源头就不准。
第二个更隐蔽:模型假设预报无偏差。但实际上每个 城市的预报都有方向性偏差——有的城市预报系统性偏 冷,有的偏热。模型不知道这件事,就会在错误的方 向上反复下注。
比如某个城市预报比实际低将近 2°C,模型觉得"温度不会到 X"是大概率,买了一堆 NO。结果实际温度每次都比预报高。
最开始的本能反应是砍城市,把表现差的停掉。砍完 发现三分之一都被禁了。这时候反应过来:需要砍三 分之一覆盖才能活的策略,问题在模型不在城市。
改了校准数据源(切到结算同源的机场观测),概率 计算加上了 bias 修正。然后把砍掉的城市全恢复了——高 σ 城市模型自己会减少信号,不需要人工禁止。
第一个:校准用的是网格再分析数据,但 Polymarket 结算用的是机场实测。两套数据源之间有系统性偏差 ,校准出来的 σ 从源头就不准。
第二个更隐蔽:模型假设预报无偏差。但实际上每个 城市的预报都有方向性偏差——有的城市预报系统性偏 冷,有的偏热。模型不知道这件事,就会在错误的方 向上反复下注。
比如某个城市预报比实际低将近 2°C,模型觉得"温度不会到 X"是大概率,买了一堆 NO。结果实际温度每次都比预报高。
最开始的本能反应是砍城市,把表现差的停掉。砍完 发现三分之一都被禁了。这时候反应过来:需要砍三 分之一覆盖才能活的策略,问题在模型不在城市。
改了校准数据源(切到结算同源的机场观测),概率 计算加上了 bias 修正。然后把砍掉的城市全恢复了——高 σ 城市模型自己会减少信号,不需要人工禁止。

- 赞赏
- 1
- 评论
- 转发
- 分享
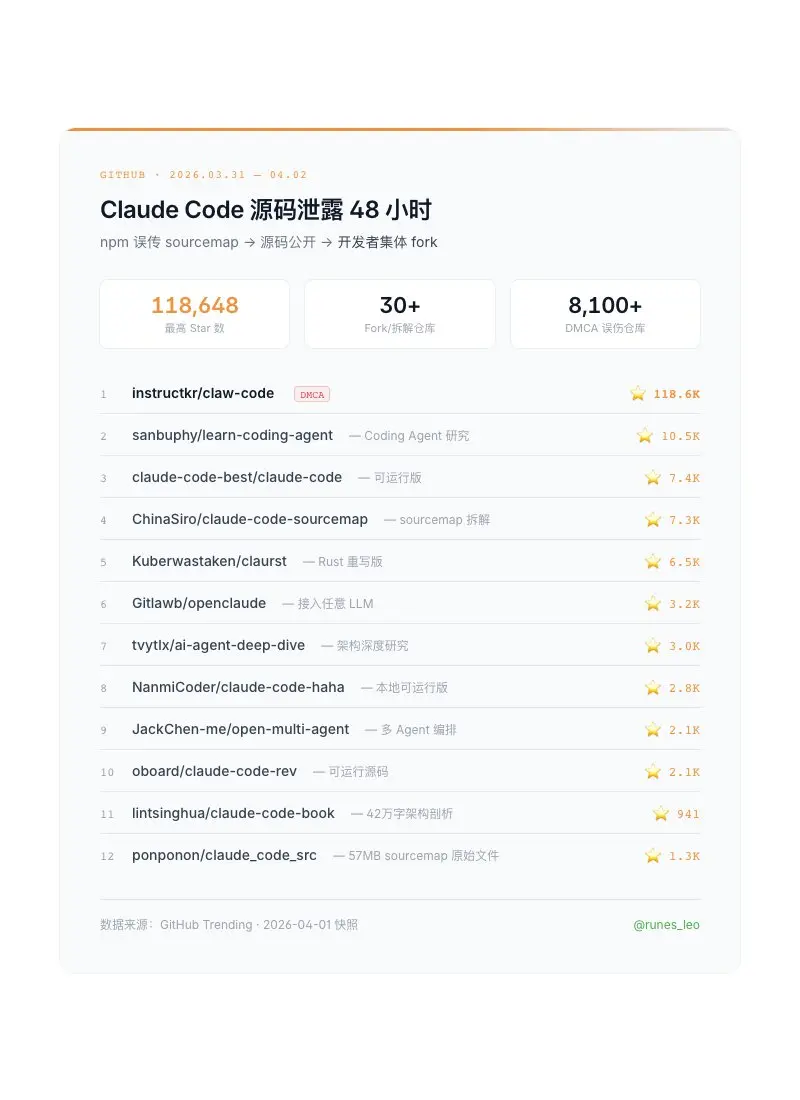
Claude Code 51 万行源码泄露,GitHub 一夜冒出十几个备份仓库,最高 11.8 万星。
中文开发者圈集体狂欢,拆架构、挖隐藏功能、找 feature flag。
但最反直觉的是 Anthropic 的反应:
npm 包没撤。没紧急公关。首席商务官 Paul Smith 出来说了句:"absolutely not breaches or hacks"——不是安全事故,是流程问题。
对比一下:如果 Tesla 自动驾驶源码泄了,马斯克会说"流程问题"就完了?
Anthropic 敢这么淡定,因为心里清楚:Claude Code 的竞争力从来不在那 51 万行 TypeScript 里。harness 是壳,模型是魂。你拿到了壳,塞不进那个魂。
GitHub 上那些 fork 已经证明了——大部分在做的事是"怎么绕开 Anthropic API 跑起来",而不是"怎么用这套架构做个更好的产品"。
开发者以为拿到了源码就拿到了 Claude Code。Anthropic 知道他们只是拿到了说明书。
中文开发者圈集体狂欢,拆架构、挖隐藏功能、找 feature flag。
但最反直觉的是 Anthropic 的反应:
npm 包没撤。没紧急公关。首席商务官 Paul Smith 出来说了句:"absolutely not breaches or hacks"——不是安全事故,是流程问题。
对比一下:如果 Tesla 自动驾驶源码泄了,马斯克会说"流程问题"就完了?
Anthropic 敢这么淡定,因为心里清楚:Claude Code 的竞争力从来不在那 51 万行 TypeScript 里。harness 是壳,模型是魂。你拿到了壳,塞不进那个魂。
GitHub 上那些 fork 已经证明了——大部分在做的事是"怎么绕开 Anthropic API 跑起来",而不是"怎么用这套架构做个更好的产品"。
开发者以为拿到了源码就拿到了 Claude Code。Anthropic 知道他们只是拿到了说明书。
- 赞赏
- 1
- 1
- 转发
- 分享
Poponaq:
GaS 继续我的 Claude Code 终端里住着一只毒舌幽灵。
/buddy 一敲,蹦出来一张属性卡:Ghost,COMMON 稀有度,五维属性最高的一项是 SNARK——82 分。调试能力 19,耐心 14,但嘴毒值拉满。
它会根据你当前对话实时吐槽。我刚试完所有命令发现改不了名字,它立刻说:
▎ "Yet another user discovers limitations. Shocking." 又一个用户发现了限制。真令人震惊。
整个 buddy 系统藏了不少细节:18 种物种(从鬼魂到水豚到蘑菇),5 档稀有度,还有 1% 概率的闪光版。你的物种是账号 ID 哈希决定的,换不了——盐值字符串里藏着 friend-2026-401,401 是愚人节。
怎么玩:
• /buddy — 孵化你的宠物,看看命运给你分了什么
• /buddy card — 查属性卡,看你的峰值是智慧还是毒舌
• /buddy pet — 摸一下,有爱心动画
• 直接喊它名字,它会代替 Claude 回你话
• 不喜欢抽到的物种?装个 buddy-reroll 重新摇
现在每次调试出 bug,它就在旁边阴阳怪气。SNARK 82 不是白给的。
/buddy 一敲,蹦出来一张属性卡:Ghost,COMMON 稀有度,五维属性最高的一项是 SNARK——82 分。调试能力 19,耐心 14,但嘴毒值拉满。
它会根据你当前对话实时吐槽。我刚试完所有命令发现改不了名字,它立刻说:
▎ "Yet another user discovers limitations. Shocking." 又一个用户发现了限制。真令人震惊。
整个 buddy 系统藏了不少细节:18 种物种(从鬼魂到水豚到蘑菇),5 档稀有度,还有 1% 概率的闪光版。你的物种是账号 ID 哈希决定的,换不了——盐值字符串里藏着 friend-2026-401,401 是愚人节。
怎么玩:
• /buddy — 孵化你的宠物,看看命运给你分了什么
• /buddy card — 查属性卡,看你的峰值是智慧还是毒舌
• /buddy pet — 摸一下,有爱心动画
• 直接喊它名字,它会代替 Claude 回你话
• 不喜欢抽到的物种?装个 buddy-reroll 重新摇
现在每次调试出 bug,它就在旁边阴阳怪气。SNARK 82 不是白给的。
- 赞赏
- 点赞
- 评论
- 转发
- 分享
升级 Claude Code v2.1.89 之后,终端里的对话往上滚就没了,历史消息直接“消失”。
不是模型把上下文压缩了,是新版的渲染引擎改了——虚拟化滚动,只渲染当前视口内容 ,历史消息在界面上"消失"了。
iTerm2、自带终端都一样,问题在 Claude Code 这一层。
解法很简单:用 tmux 包一层。
tmux 有自己独立的 scrollback buffer,不受应用层渲染影响。配置三行就够:
set -g history-limit 50000
set -g mouse on
set -sg escape-time 10
50000 行历史,鼠标滚轮直接翻,ESC 延迟调低不影响交互。
我加了个 shell 函数,打 cc 自动起 tmux + Claude Code,已有 session 直
不是模型把上下文压缩了,是新版的渲染引擎改了——虚拟化滚动,只渲染当前视口内容 ,历史消息在界面上"消失"了。
iTerm2、自带终端都一样,问题在 Claude Code 这一层。
解法很简单:用 tmux 包一层。
tmux 有自己独立的 scrollback buffer,不受应用层渲染影响。配置三行就够:
set -g history-limit 50000
set -g mouse on
set -sg escape-time 10
50000 行历史,鼠标滚轮直接翻,ESC 延迟调低不影响交互。
我加了个 shell 函数,打 cc 自动起 tmux + Claude Code,已有 session 直
- 赞赏
- 1
- 评论
- 转发
- 分享
盘了一下我的 Claude Code,全局挂了 12 个 MCP。
每个 MCP 的工具描述是常驻 system prompt 的,不管你调不调,都在吃 context。
拉了 14 天调用数据:6 个两周加起来不到 10 次。直接砍到 6 个。
砍完在想一个问题:哪些工具该用 MCP,哪些用 CLI 就够了?
MCP 的优势是结构化——Claude 能看到参数 schema,直接调用,处理复杂交互(登录态、长连接、多步操作)也更稳。
但代价是常驻 context。你装 10 个 MCP,就是几十个工具描述永远挂在那。
CLI 没有这个开销。命令只在你跑的时候才进 context,跑完就消失。
我现在的做法:需要 Claude 主动发现和调用的留 MCP(记忆系统、TG 消息),其余能 CLI 化的都 CLI 化。
全局 MCP 控制在 5-6 个以内,其余按项目按需加载。
每个 MCP 的工具描述是常驻 system prompt 的,不管你调不调,都在吃 context。
拉了 14 天调用数据:6 个两周加起来不到 10 次。直接砍到 6 个。
砍完在想一个问题:哪些工具该用 MCP,哪些用 CLI 就够了?
MCP 的优势是结构化——Claude 能看到参数 schema,直接调用,处理复杂交互(登录态、长连接、多步操作)也更稳。
但代价是常驻 context。你装 10 个 MCP,就是几十个工具描述永远挂在那。
CLI 没有这个开销。命令只在你跑的时候才进 context,跑完就消失。
我现在的做法:需要 Claude 主动发现和调用的留 MCP(记忆系统、TG 消息),其余能 CLI 化的都 CLI 化。
全局 MCP 控制在 5-6 个以内,其余按项目按需加载。

- 赞赏
- 3
- 1
- 转发
- 分享
victoravn:
非常好的项目我每天会扫一遍 GitHub 热门项目,找能优化自己工作流的东西。今天筛出来发现一半都是 Claude Code 生态的,挑三个值得看的:
claude-code-best-practice(+2407⭐)
整理了 87 条 CC 使用技巧 + 8 种社区工作流对比。刚上手或者用了一阵想系统化的都适合翻一遍。
oh-my-claudecode(+1126⭐)
多 Agent 编排框架,19 个预设 Agent + 自动模型路由(简单任务走 Haiku 省钱,复杂的自动升 Opus)。最有意思的是它能从调试过程中自动提取可复用的 skill,不用你手动写。适合已经用 CC 干活、想上团队协作的。
superpowers(+2620⭐,总星 128K)
Jesse Vincent 做的 Agent 技能框架,核心是测试驱动 + Git worktree 隔离。适合对代码质量有要求、不想让 Agent 乱改代码的。
按阶段选:入门看 best-practice,干活看 superpowers,搞团队看 oh-my-claudecode。
claude-code-best-practice(+2407⭐)
整理了 87 条 CC 使用技巧 + 8 种社区工作流对比。刚上手或者用了一阵想系统化的都适合翻一遍。
oh-my-claudecode(+1126⭐)
多 Agent 编排框架,19 个预设 Agent + 自动模型路由(简单任务走 Haiku 省钱,复杂的自动升 Opus)。最有意思的是它能从调试过程中自动提取可复用的 skill,不用你手动写。适合已经用 CC 干活、想上团队协作的。
superpowers(+2620⭐,总星 128K)
Jesse Vincent 做的 Agent 技能框架,核心是测试驱动 + Git worktree 隔离。适合对代码质量有要求、不想让 Agent 乱改代码的。
按阶段选:入门看 best-practice,干活看 superpowers,搞团队看 oh-my-claudecode。

- 赞赏
- 2
- 评论
- 转发
- 分享
Claude 响应变得好慢,和我开8个终端窗口有关系吗?
- 赞赏
- 点赞
- 评论
- 转发
- 分享
热门话题
查看更多27.19万 热度
1.69万 热度
8.42万 热度
1.25万 热度
28.29万 热度
置顶
🔥 WCTC S8 全球交易赛正式开赛!
8,000,000 USDT 超级奖池解锁开启
🏆 团队赛:上半场正式开启,预报名阶段 5,500+ 战队现已集结
交易量收益额双重比拼,解锁上半场 1,800,000 USDT 奖池
🏆 个人赛:现货、合约、TradFi、ETF、闪兑、跟单齐上阵
全场交易量比拼,瓜分 2,000,000 USDT 奖池
🏆 王者 PK 赛:零门槛参与,实时匹配享受战斗快感
收益率即时 PK,瓜分 1,600,000 USDT 奖池
活动时间:2026 年 4月 23 日 16:00:00 -2026 年 5 月 20 日 15:59:59 UTC+8
⬇️ 立即参与:https://www.gate.com/competition/wctc-s8
#WCTCS8🎁 积分换豪礼!成长值第 1️⃣ 8️⃣ 期社区抽奖狂欢开启!
新老用户 100% 中奖,完成日常任务即可参与抽奖!
👉 https://www.gate.com/activities/pointprize?now_period=18
🌟 如何参与?
1️⃣ 进入【广场】个人主页,点击头像旁积分标识进入【社区中心】
2️⃣ 完成发帖、评论、点赞、发言等广场或热聊任务赚取成长值
🎁 每满 300 积分即可抽奖 1 次,MacBook Air M5、Gate 13 周年礼盒、VIP 体验卡等您来拿!
🔥 本期门槛再降低:仅需完成 20U 现货交易,即可获得发奖资格!
详情 👉 https://www.gate.com/announcements/article/5085410,000 USDT 悬赏,寻找跟单金牌星探!🕵️
挖掘顶级带单员,赢取高额跟单体验金!
立即参与:https://www.gate.com/campaigns/4624
🎁 三大活动,奖金叠满:
1️⃣ 慧眼识英:发帖推荐带单员,分享跟单体验,抽 100 位送 30 USDT!
2️⃣ 强力应援:晒出你的跟单截图,为大神打 Call,抽 120 位送 50 USDT!
3️⃣ 社交达人:同步至 X/Twitter,凭流量赢取 100 USDT!
📍 标签: #跟单金牌星探 #GateCopyTrading
⏰ 限时: 4/22 16:00 - 5/10 16:00 (UTC+8)
详情:https://www.gate.com/announcements/article/50848✍️ Gate 广场「创作者认证激励计划」进行中!
我们欢迎优质创作者积极创作,申请认证
赢取豪华代币奖池、Gate 精美周边、流量曝光等超 $10,000+ 丰厚奖励!
立即报名 👉 https://www.gate.com/questionnaire/7159
📕 认证申请步骤:
1️⃣ App 首页底部进入【广场】 → 点击右上角头像进入个人主页
2️⃣ 点击头像右下角【申请认证】进入认证页面,等待审核
让优质内容被更多人看到,一起共建创作者社区!
活动详情:https://www.gate.com/announcements/article/47889