Epoch AI 报告:Anthropic 人均创收 900 万美元,高出 OpenAI 逾 60%

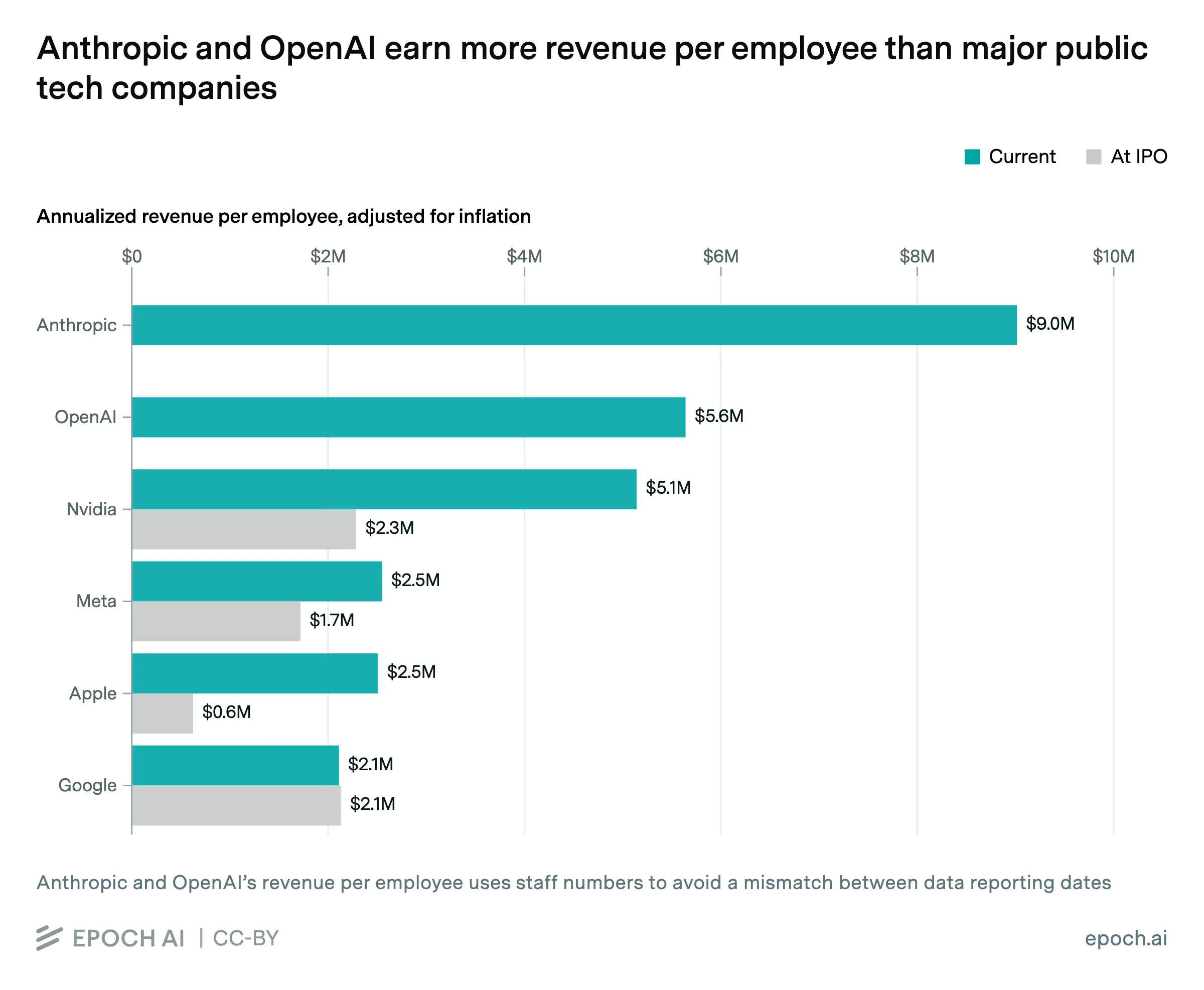
根据人工智能研究机构 Epoch AI 于 5 月 8 日发布的数据洞察,研究员 Luke Emberson 估算,Anthropic 每名员工创收约 900 万美元,OpenAI 每名员工创收约 550 万美元,二者均超过《福布斯》全球企业 2000 强榜单上所有大型上市科技公司的人均创收水平。
数据估算方法与主要比较指标
(来源:Epoch AI)
根据 Epoch AI 研究员 Luke Emberson 的数据洞察,上述估算并非基于公司公开财务报表,而是采用媒体公开报道及员工人数平均增速进行推算。Epoch AI 在报告中指出,企业在年化收入达到百亿美元规模时仍能维持人均创收的高速增长,在科技行业发展史中属于罕见现象。
主要人均创收数据比较:
Anthropic:约 900 万美元
OpenAI:约 550 万美元
英伟达(NVIDIA):约 510 万美元(业内参照)
Epoch AI 同期研究报告:AI 芯片走私估算与供应链分析
在同一期 Epoch AI 周报中,研究员 Isabelle Zuniewicz 发布了关于 AI 芯片走私的估算报告,估计截至 2025 年,约有 29 万至 160 万个 H100 级 AI 处理器走私至中国,中位数估算约 66 万个,约相当于中国 AI 总算力的三分之一。该估算采用两类依据:偏离合法供应链的数据,以及在中国灰色市场转售的数 据。
Epoch AI 同时推出 AI 芯片组件数据浏览器,追踪自 2024 年以来先进 AI 芯片供应链中的三个关键元件:先进节点逻辑、高频宽内存(HBM)及芯片封装(CoWoS)。研究员 Venkat Somala 在相关文章中指出,高频宽内存(HBM)已成为主要成本与主要供应链瓶颈。
本期为 Epoch AI 首期周刊,此前为月刊发行。
常见问题
Epoch AI 对 Anthropic 及 OpenAI 人均创收的估算方法为何?
根据 Epoch AI 研究员 Luke Emberson 于 2026 年 5 月 8 日发布的 数据洞察,估算基于媒体公开报道及员工人数平均增速,非基于公司公开财务报表,Anthropic 估算约 900 万美元,OpenAI 估算约 550 万美元。
英伟达的人均创收在此次报告中处于何种水平?
根据 Epoch AI 报告,英伟达人均创收约 510 万美元,低于 Anthropic 的 900 万美元及 OpenAI 的 550 万美元,但在《福布斯》全球企业 2000 强榜单的大型上市科技公司中属于较高水平。
Epoch AI 对 AI 芯片走私至中国的估算结论为何?
根据 Epoch AI 研究员 Isabelle Zuniewicz 的报告,截至 2025 年,约有 29 万至 160 万个 H100 级 AI 处理器走私至中国,中位数估算约 66 万个,约占中国 AI 总算力的三分之一。
相关快讯
Cerebras 首次公开募股认购超额 20 倍,定价区间或上调至每股 135 美元
Cloudflare 第 1 季财报:收入 6.398 亿超预期,AI 应用导致裁员 1100 人
白鲸实验室:DeepSeek 与阿里巴巴“融资”谈判未能达成协议
AI 芯片需求火热,Cerebras IPO 超额认购逾 20 倍
Anthropic 针对 $1T 估值,投资者追逐 Claude 的企业级增长