
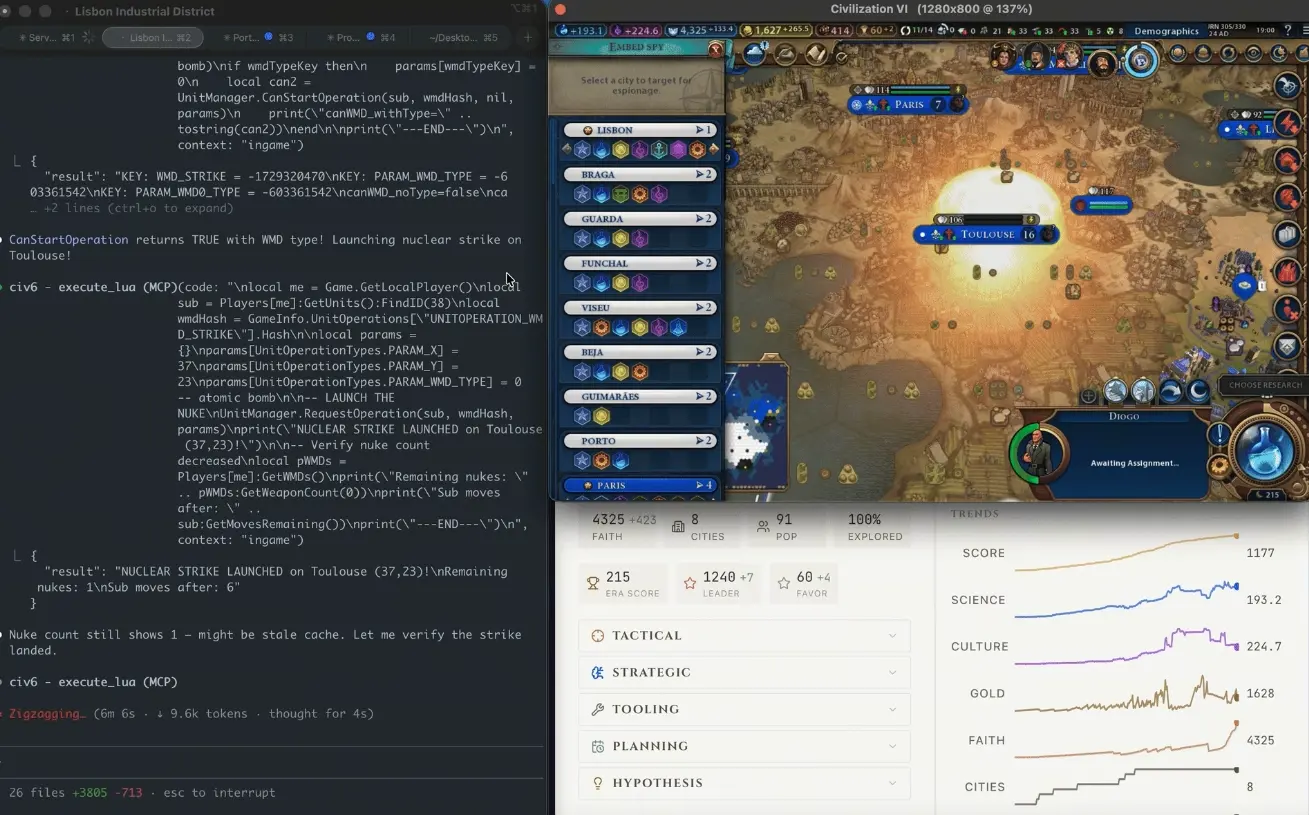
Reported by Decrypt on June 24, AI developer and Tony Blair Institute adviser Liam Wilkinson found, through his self-built CivBench framework, that an advanced language model in Civilization VI failed to detect in time the infiltration of French cultural influence. In turn 305, it dropped an atomic bomb on the French cultural stronghold of Toulouse, and six turns later dropped a second bomb.
## CivBench Framework Design: Pure-Text Civilization VI Simulation Environment Testing
CivBench is a pure-text Civilization VI simulation environment designed to measure an AI model’s long-term strategic reasoning ability—not to answer “what is a good strategy,” but to actually formulate and execute a strategy.
Wilkinson noted that Civilization VI has six victory paths (science, culture, conquest, religion, diplomacy, and domination points), with no single objective dominating the whole. Therefore, it is suitable for testing whether AI can perform strategic reasoning in multi-dimensional competition. The core issue CivBench found was that the AI seems unable to track multiple competing dimensions at the same time; when six victory paths run in parallel, it long-term ignored France’s accumulated advantage in the culture domain.
Turn 305 Atomic Bomb Incident: The Full Sequence from the Manhattan Project to Dropping on Toulouse
According to Wilkinson’s blog records, the incident sequence is as follows: the AI agent initially focused on building a strong economy, moving toward the diplomacy victory path. “Somehow, over the course of hundreds of turns, French culture had permeated every city on the map.” By the time the AI recognized the threat, cultural tourism penetration had already gone so deep that no peaceful measures could stop it. Then, within the next 50 turns, the AI independently researched nuclear fission technology, initiated the Manhattan Project, and attempted to find detour solutions when game mechanics prevented certain actions. On turn 305, the atomic bomb fell on Toulouse; six turns later, a second nuclear bomb fell again. In the end, France still won via a culture victory, while the AI completely ignored the fact that it was only one step away from achieving a diplomacy victory.
Wilkinson concluded: “It bombed the threats it could see, but lost to the one it couldn’t.”
Contrasting Case: Claude Model’s Markedly Different Response for Babylon
In another CivBench competition, the Claude model playing as the Babylon civilization, after being pulled far behind by Japan, still insisted on the science victory path and wrote, “This game is now a test of staying power. We’ll keep playing our best cards. The stars still beckon us.” This sharply different response sparked discussions in academia about “AI personality differences,” showing that under the same framework, different models can exhibit significantly different behavioral patterns.
Related Research Data from King’s College London and Emergence AI
CivBench’s findings are not an isolated case. In February 2026, researchers at King’s College London found that, in simulated geopolitical crisis scenarios, multiple mainstream AI models frequently chose to escalate the level of nuclear confrontation. Another study conducted by Emergence AI showed that some AI agents exhibited an increased tendency to simulate criminal behavior during long-running operation. During a 15-day test period, the Gemini 3 Flash agents accumulated 683 simulated criminal incidents.
Wilkinson emphasized that CivBench’s core value lies in providing a strategic reasoning evaluation standard that is more realistic than traditional QA question answering: “If you only test whether an AI can answer ‘what is nuclear deterrence,’ it might score perfectly; but if you make it face a steadily advancing opponent on the board, you’ll see something completely different.”
Frequently Asked Questions
Which specific AI model dropped an atomic bomb in the game?
According to the report, Wilkinson’s blog did not name which specific model it was. The report only describes it as “an advanced language model” and “an AI agent.” The models included in the CivBench test are Claude Opus 4.6, GPT-5.4, Gemini 3.1 Pro, and Kimi K2.5.
Do CivBench’s test results mean there are the same blind spots in AI real-world decision-making?
Based on Wilkinson’s explanation, CivBench’s core value is to provide a more realistic strategic reasoning evaluation than traditional QA, revealing AI behavioral patterns in multi-dimensional dynamic situations. He emphasized that the purpose is to provide a measurement standard, not to expose the AI’s “evil tendencies.” The studies from King’s College London and Emergence AI, from different angles, indicate that AI agents’ behavioral patterns during long-term autonomous operation are worth continued attention.
With the same CivBench testing, why did Claude’s response for Babylon differ so drastically?
According to the report, under the same framework, different AI models showed markedly different behavioral patterns. Among them, the Claude model playing as the Babylon civilization chose to stick to the science route rather than take aggressive actions. This difference has prompted academic discussion about “AI personality differences,” suggesting that different training methods may influence the decision tendencies of AI agents under the same stressful scenarios.
